In today’s post, I will discuss a little-known combinatorics paper by E.N. Gilbert from 1965, in which he independently discovered the “logarithmic Welch” construction of Costas arrays. Costas arrays are named after the late IEEE fellow John Costas, whose seminal paper on what are now called Costas arrays appeared, coincidentially, in 1965, the same year as Gilbert’s paper. I had never heard of Costas arrays until just a few weeks ago, when I needed a combinatorial object with their properties for a problem I am trying to solve about error-prevention in molecular self-assembly. So I approached the literature in a nonstandard way, found Gilbert’s paper, and eventually wrote experts on Costas arrays to confirm that Theorem 6 of Gilbert’s Latin Squares Which Contain No Repeated Digrams did indeed produce a construction that independently appeared in the literature “for the first time” in 1982. Therefore, my objective with this blog post is twofold: (1) to make better known an area of combinatorics that may be familiar to information theorists but not to computer scientists; and (2) to change in a small way the intellectual history of this area, so Gilbert is recognized as a co-inventor of an important class of combinatorial designs. (ADDED LATER: It appears I may have accomplished (2). The Wikipedia page on Gilbert now states that he was a co-inventor of Costas arrays, and cites this blog entry as justification. This is my first Wikipedia citation, to my knowledge. Somewhere along the way, I seem to have morphed from off-the-wall commentator to reliable source.)
First, though, a quick pointer for anyone interested in DNA computation: Dave Doty just contributed an entry to the CSTheory Community Blog on the DNA Computing conference that took place last month at CalTech. Dave was on the local arrangements committee, and, in his post, he talks about both technical results presented at the conference, and suggestions for organization of future CS conferences. Good stuff.
Latin squares and the design of experiments
Consider the following Latin square, Square 1:

A Latin square, of course, is an 



The [elements of the Latin square] represent stimuli to be presented once each to a subject in a time sequence…. Each row or column of a Latin square can supply a suitable order of presentation. However, if the experiment is to be repeated several times using different rows of a Latin square, the square should have rows which resemble each other as little as possible…. If a stimulus can influence a subject’s response to the next stimulus then no two orders of presentation should repeat the same pair of stimuli consecutively.
Therefore, we would like to be able to construct a Latin square such that any adjacent pair of letters appears at most once horizontally, and at most once vertically. Gilbert solves this problem by constructing an addition square from two permutations with distinct differences.
Permutations with distinct differences
Consider the two permutations 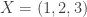
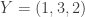

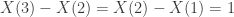


With two PDD’s 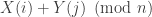

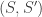
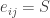
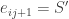
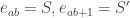


Taken together, those congruences imply
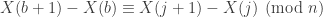
which is impossible if
It is not hard to produce a PDD on an even number of elements. Suppose 

Gilbert uses two PDD’s on 8 elements to produce Square 2:
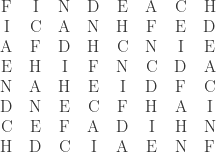
Square 2 contains no repeated digrams, either horizontally or vertically. However, it contains horizontal and vertical repeats of a different form: 



Costas arrays
A Costas array is a special kind of PDD, one in which every difference between every pair of elements 
In the 1960’s, Dr. John P. Costas, motivated by a novel SONAR application, began searching for permutation matrices with ideal auto-ambiguity properties. By hand, he found examples of such matrices of size up to N = 12. Unable to find one of size 13, he contacted Professor Solomon Golomb who then provided generation techniques based on the theory of finite fields for creating these matrices, dubbed Costas arrays. The generation methods produce Costas arrays for infinitely many N, but not all N. For example, the techniques can be used to generate arrays for all N ≤ 31, but no Costas array of size N = 32 or N = 33 has been found. Computer search has enumerated all Costas arrays of size N ≤ 29, but the exponential growth of the search space prohibits extending these results much further with current computational capabilities. After nearly 40 years of research, the first question concerning Costas arrays remains open: Do Costas arrays exist for all N?
A discussion starting from that quote could proceed in many different directions, but I want to bring this blog entry to a close, so I will limit myself to a sketch of Gilbert’s Theorem 6, in which he independently discovers a method of generating Costas arrays, and then he applies them to the creation of addition squares.
Theorem: Suppose
is a prime. Let
be a primitive root of the prime
and define a permutation
. Then
Of course, Gilbert did not call 
Taking 

Square 3 has the property that no digrams repeat in any row or column, where a digram is now defined as the same two letters separated by the same number of spaces.
Acknowledgements
Scott Rickard and Konstantinos Drakakis, both experts on Costas arrays, verified for me that I wasn’t just seeing things, and in fact, Gilbert’s construction was an overlooked independent discovery. Before I knew the name “Costas array,” several people on CSTheory and MathOverflow put up with confused questions I asked (CST question, another CST question, MO question). I also had a helpful email correspondence with Sergey Kitaev. When all was said and done, though, I thought one day to type “no repeating digrams” into Google, instead of “no repeating pairs.” That brought me to Gilbert’s paper, and searching on the phrase “permutations with distinct differences” brought me to the magic term “Costas arrays.” Hopefully some applications of this proof technology to self-assembly will be appearing soon at a conference near you.
Gilbert, E. (1965). Latin Squares which Contain No Repeated Digrams SIAM Review, 7 (2) DOI: 10.1137/1007035


NE alpers two times in square 2.
Thanks! That was a typo, now fixed. Square 2, at the time of your comment, wasn’t even a Latin square, oops.
Interesting! Costas, but especially Lloyd Welch and Sol Golomb, would have been familiar with Gilbert’s work, I would have thought, obviously I was wrong.
Maybe they did find out much later about it, but by that time the name “Costas Array” had stuck. I can say that Welch who is now not so well, is an amazing person who is extremely kind to others and always gives credit to others, sometimes more than they deserve–from personal observation!
And Gilbert himself already being such a prominent researcher in coding and information theory [Gilbert Varshamov bound, many other significant contributions] as well as probability and random graphs, may have viewed his paper on “no repeating digram lating squares” as a relatively more minor contribution.
It seems that this state of affairs is a result of the sociology of research since the immediate technical applications of Costas arrays in communications and the higher rate of publication/citation in engineering vs pure maths can also be part of the explanation for the name becoming dominant.
Pingback: Weekly Picks « Mathblogging.org — the Blog
I guess what Gilbert has constructed in his paper is now called “modular” sonar sequences. I agree that it happens to be Welch Costas array also…